






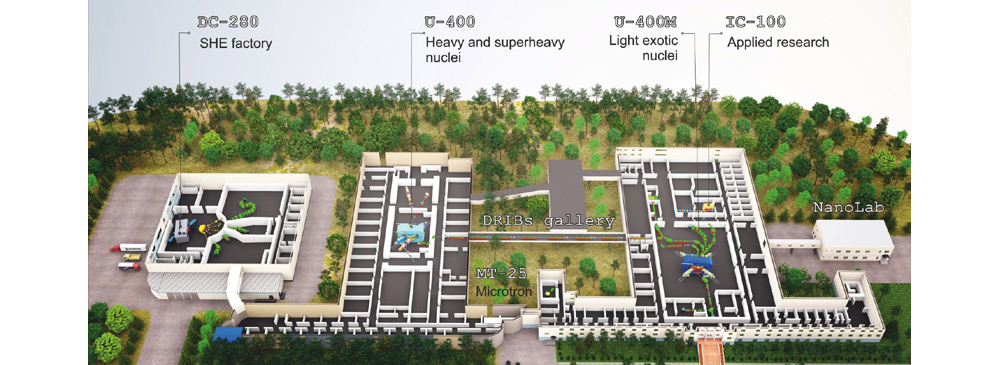


![]()
990
научных центров и университетов сотрудничает с ОИЯИ
![]()
1500
научных статей и докладов ежегодно публикуют сотрудники ОИЯИ
![]()
60
международных конференций и совещаний ежегодно проводится в ОИЯИ




26 марта 2026, Первый канал
70-летие отмечает Объединенный институт ядерных исследований в Дубне
Подробнее26 марта 2026, ВГТРК/ГТК «Телеканал «Россия»
70 лет Объединенному институту ядерных исследований в Дубне: международный праздник науки
Подробнее25 марта 2026, Минобрнауки РФ
«Наука сближает народы»: 70 лет Объединенному институту ядерных исследований
Подробнее25 марта 2026, Наука Mail
Таблица Менделеева не закончена: в Дубне ищут то, чего еще не существует
Подробнее04 марта 2026, Минобрнауки России
Валерий Фальков провел рабочую встречу с директором Объединенного института ядерных исследований Григорием Трубниковым
Подробнее02 марта 2026, ИГУ